

RS01-用户画像


用户网络行为画像
James
2019-05-23
什么是用户画像
用户画像(User Portrait)是用来勾画用户(用户背景,特征,性格标签,行为场景等)和联系用户需求与产品设计的,旨在通过从海量用户行为数据中炼银挖金,尽可能全面的抽出一个用户的信息全貌,从而帮助解决如何把数据转化为商业价值的问题。
对于电商行业来说,用户画像是对同一类用户进行不同维度的刻画,就是将买家进一步细分和具象,如分为闲逛型用户、收藏型用户、比价型用户、购买型用户等。
用户画像的颗粒度
颗粒度是指用户画像细化的程度。
颗粒度越小,用户画像越细化,对用户的刻画就越精细,也就更加有利于提高推荐系统的准确性。然而颗粒度越小,要求获取用户越细化的数据,提高了用户画像的建模成本,同时导致用户画像适用性降低。
用户定性画像
标签是人工定义的高度精炼的特征表示。语义化和短文本是标签呈现出的两个重要特征。
- 语义化:让人们容易理解
- 短文本:方便计算机提取
标签化是用户定性画像的核心。
在视频推荐应用中,相关的知识类型主要有以下三种:
与用户和视频特征有关的属性知识
例如用户的年龄,性别,视频类型,时长,主演,导演,地区等。
反应用户兴趣偏好的规则知识
其中规则的左部一般包括用户、视频的属性特征,以及用户观看视频的行为事实,规则的右部则是有关用户兴趣偏好的结论。
用于推理和确保关系完整性、正确性的约束性知识
一般为专家经验,也可以利用数据挖掘和机器学习技术自动学习规则,然后由知识工程师进行过滤。
本体论(Ontology)
为方便对用户画像建模中设计的各类知识进行统一表示和管理而引入的研究客观事物存在和组成的通用理论。
本体的结构一般包括类(Class),属性(Property),实例(Individual),公理(Axioms)和推理规则(Rules)。
- 类是对领域中具有相同性质的概念或术语的一种抽象,每个类通常又包含若干子类,形成一定的类层次结构。
- 属性是对类概念的描述。
- 实例则是描述本体中类的具体参数
- 公理是本体中的永真式,用于描述类概念间的约束条件,并且这一条件在领域中是永远成立的。
- 推理规则是对本体所在领域中的专家知识的一种形式化表示。
本体构建的步骤
构建领域词汇表
领域词汇表一般包含类词汇表和属性词汇表,词汇表中包含词条名称,类型,语义描述,所属类别等信息。构建领域词汇表有助于本体概念分析,保证设计知识的完整性,去除冗余,为划分类的层次关系和属性间的层次关系奠定基础。
确定类与类之间的结构
领域概念的分类层次是将概念进行分类组织,用于描述领域该年间的类书关系,并将本体中的概念模块化,保证没有重复的概念,防止冗余定义。
定义属性
属性包括对象属性(Object Property)和数据属性(Data Property)两种。对象属性主要用来约束两个类实例间的关系;数据属性约束类的实例。
定义实例
- 定义约束公理和推理规则
群体用户画像
群体用户画像是对目标用户群体真是特征的勾勒,是群体用户的综合原型,代表了一群真实的用户。
群体用户画像分析旨在依据不同的评估维度和模型算法,通过聚类方式将具有相同特征的用户划归成同一个族群,进而发现核心的、规模较大的用户群,从而在设计推荐系统时考虑优先满足核心用户群的需求,进一步在不存在冲突的情况下尽量满足次要用户群的需求。
群体用户画像分析的主要流程:
- 用户画像的获取
- 用户画像相似度计算
- 用户画像聚类
- 群体用户画像生成
用户画像相似度
定量相似度计算
两个用户相似度可以表示为各标签相似度的加权和。
$$sim(u_i,uj)=\sum{k}w_ksim(profile_k(u_i),profile_k(u_j))$$
其中 $w_k$ 表示第 $k$ 个标签的权重,$sim(profile_k(u_i),profile_k(u_j))$ 表示用户画像 $u_i$ 和 $u_j$ 在第 $k$ 个标签的相似度。
通常在处理定量标签时,我们需要进行归一化处理来减少不同标签数值范围不同所带来的影响。归一化方法能够将不同取值范围的定量标签数据统一到 [0,1] 区间内。常用的归一化方法有线性函数转化,对数函数转换和反正切函数转换等。
| 名称 | 公式 |
| 线性函数转换 | $y=\frac{x-x{min}}{x{max}-x_{min}}$ |
| 对数函数转换 | $y=\frac{log(x)}{log(x_{max})}$ |
| 反正切函数转换 | $y = \frac{atan(x)^2}{\pi}$ |
对于定量标签的相似度,我们可以使用欧氏距离、曼哈顿距离和余弦相似度来进行计算。
欧式距离(Enclidean Distance)
$$sim(U_i,U_j)=\sqrt{\sum_k(profile_k(U_i)-profile_k(U_j))^2}$$
曼哈顿距离(Manhattan Distance)
$$sim(U_i,U_j)=\sum_k|profile_k(U_i)-profile_k(U_j)|$$
余弦相似度
$$sim(U_i,U_j)=\sum_k\left(\frac{profile_k(U_i)}{\sqrt{\sum_kprofile_k^2(U_i)}}\times \frac{profile_k(U_j)}{\sqrt{\sum_k profile_k^2}(U_j)}\right)$$
余弦相似度没有包含用户画像各标签数值的统计特征。修正的余弦相似度通过减去群体用户画像各标签数值的平均值来改善上述缺陷。
$$sim(U_i,U_j)=\sum_k\left(\frac{profile_k(U_i)-\overline{profile(U_i)}}{\sqrt{\sum_k(profile_k^2(U_i)-\overline{profile(U_i)})^2}}\times \frac{profile_k(U_j)-\overline{profile(U_j)}}{\sqrt{\sum_k (profile_k^2}(U_j)-\overline{profile(U_j)})^2}\right)$$
Jaccard系数
对于二元变量,常用的方法是计算Jaccard系数 $$sim(U_i,U_j)=\left| \frac{Profile(U_i)\cap Profile(U_j)}{Profile(U_i)\cup Profile(U_j)}\right|$$
定性相似度计算
定性标签没有定量标签那样直接的计算相似度的方法。
定性相似度的计算方法:
- 将定性标签映射为定量标签,继而采用定量标签的相似度计算方法。
- 直接基于概念的相似度计算方法。
综合相似度计算
用户画像可能同时包含定量标签和定性标签。
最终的用户相似度是定性标签相似度和定量标签相似度的加权和。
用户画像聚类
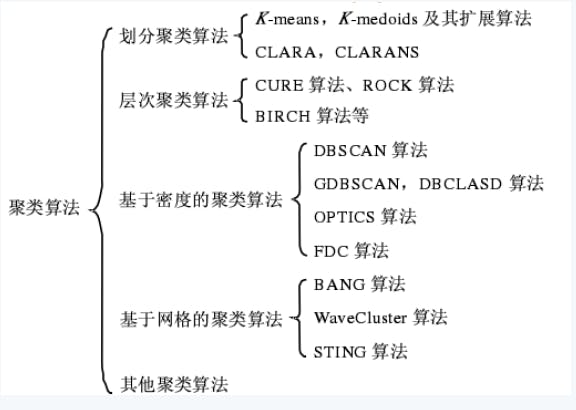
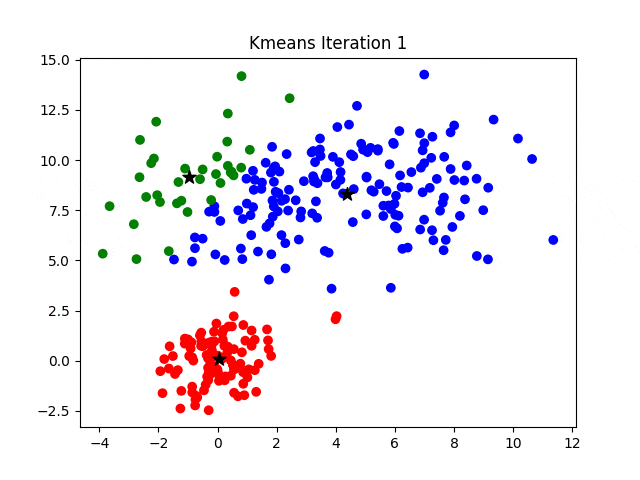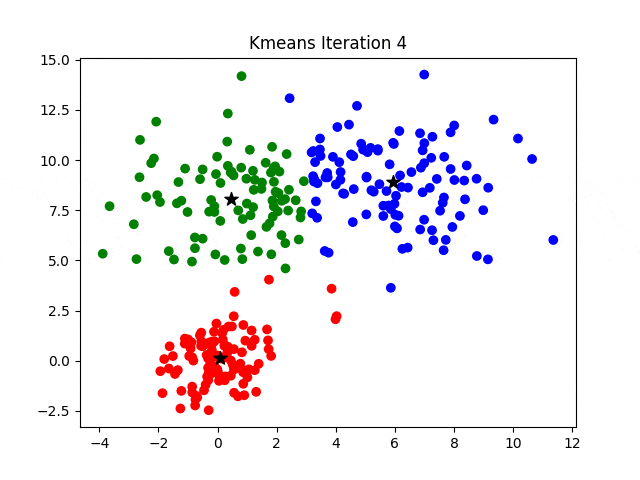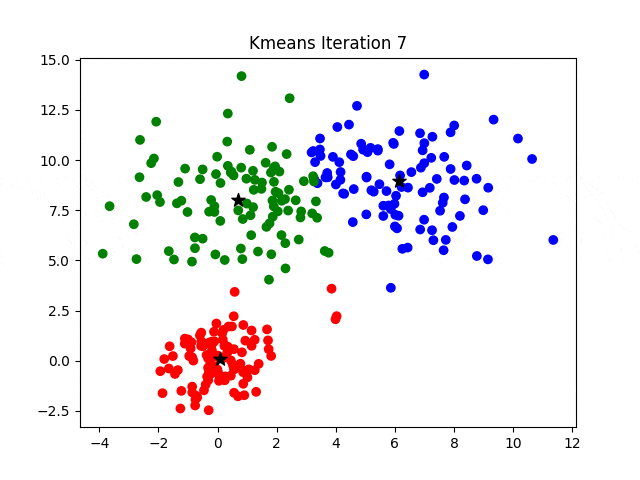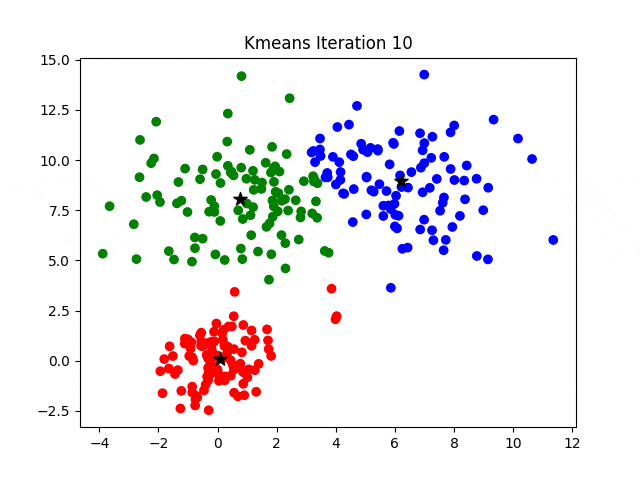
KMeans 聚类算法
- 创建初始划分,即待分类集合 $U$ 中随机取 $k$ 个元素,分别作为 $k$ 个簇的中心。
- 分别计算其余的各个元素到 $k$ 个簇中心的相似度,并将这些元素分别划归到相似度最高的簇。
- 根据上一轮聚类结果,重新计算 $k$ 个簇的中心,计算方法是取簇中所有元素各自维度的算术平均数。
- 对于 $U$ 中除去新的簇中心的所有元素,按照 2. 的方法重新聚类。
- 重复 3. 4.,直到本轮聚类结果与上一轮聚类结果相异性小于设定阈值。
- 输出聚类结果
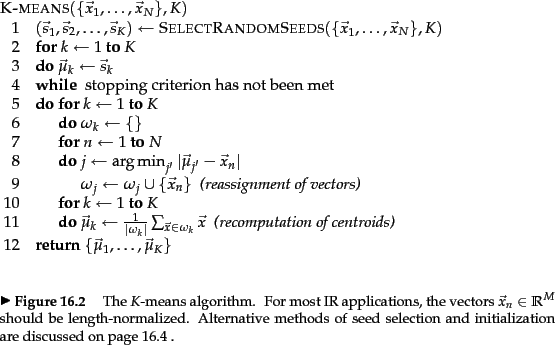
用户画像管理
用户画像的表示形式:
- 关键词法:用一组词代表用户属性
- 评分矩阵法:以二维矩阵来表示不同用户在各特征的评分
- 向量空间表示法:给出一组关键词及对应的比重
- 本体表示法:以本体模型存储用户的属性和关系
用户画像通常使用列数据库及Key-Value数据库存储。
用户画像的更新机制:
- 当新增数据量达到一定阈值时
- 定时更新
- 当新增用户画像和原有用户画像差异达到一定阈值时